Written by Thomas Harlan, Jim McGrath; Reporting Services Team - iatricSystems

Wait, what is “time blocking”?
It’s generating a list of start and end dates/times in a result set, and then using that set of rows to do something else, like:
We use the time block result set as our starting point, rather than attributing dates/times based on something else. Remember that you can’t always count on an event happening on a day and time.
To quickly and easily generate the kinds of sets below, here are links to the Code:

Like so...
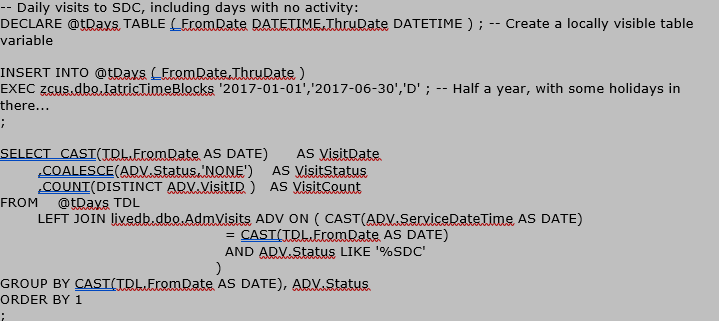
Note that since we’re using a stored procedure to get the time block, we need to create a table variable to hold the output. Then we use @tDays as the FROM table from which to start, and we LEFT JOIN to AdmVisits because we want to make sure we still have a row from @tDays even when there are no visits on that day.
However, we also want to see the SDC visit count, but not lose the original row from @tDays. So, we can’t use the WHERE clause to do LIKE ‘%SDC’ because then the days with no visits will drop. This means we move that criteria into the ON (=) clause in the LEFT JOIN.
If you haven’t used criteria inside your ON (=) besides the linking fields, this may look odd! But it works. You can use whatever criteria you want there, since a JOIN to another table is really a query to another table.
Also note that our ADV.Status field in the SELECT list needs a COALESCE() to provide a value for days where there are no visits. We also need to account for COUNT() needing to report a zero on days when there are no visits… If you use COUNT(*) you will get at least 1 in the field (because @tDays has a value even when AdmVisits does not).
Time Blocking in SQL Server Integration Services
Another handy practice is to use the time block recordset to create sets of files for a vendor on those days when the implementation team of your revenue cycle project comes around and says something like:
“You know those daily files you have scheduled for us? We need five years of historical data, with one set of files per calendar month. Can you get us that tomorrow?”
That’s either 12 x 5 = 60 manual runs of your code or one run of an SSIS package with time blocking baked in. This has happened to me more than once, so now I use a template SSIS .dtsx to start, which implements this structure for me from the get-go.
To set it up by hand:
In the Variables pane of your SSIS package…
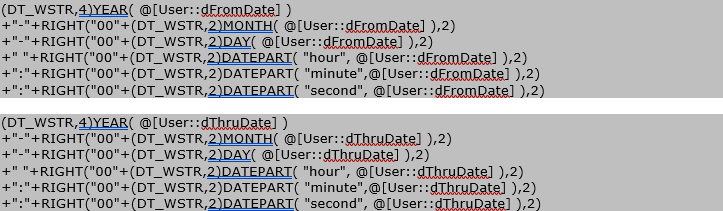

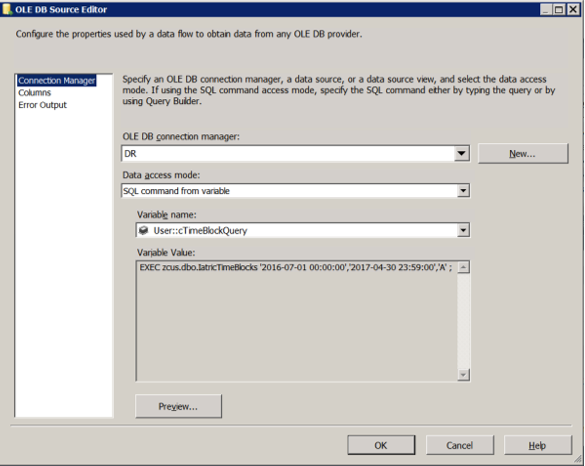
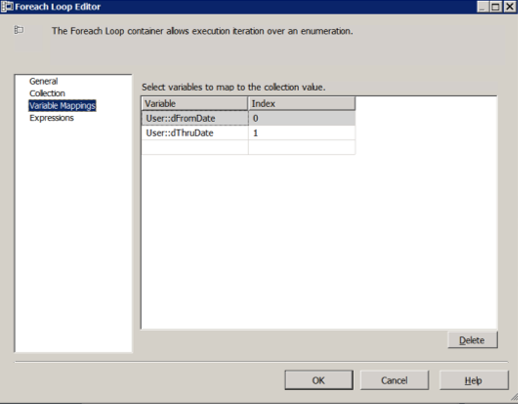
You can also get the same kind of results by creating a Date Dimension table in [zcus] and populating it with all of the time points you’re interested in from 1753-01-01 to 9999-12-31, and then using a select against that table to get the components you want.
Extra Credit
Create a table-valued function version of the stored procedure, which is more practical in reporting code, where the sp is handier when used in SSIS.
If you need more help…Our Report Writing team can help you fix reports, create new ones, make old ones faster, and much more. Simply reach out to your Iatric Systems Account Executive or our NPR report writing team at reportwriting@iatric.com to discuss how we can help support your team!

