Written by Thomas Harlan, Reporting Services Team - iatricSystems
![]() This tip is a shout-out to all the reporting folks still working with MEDITECH C/S or Magic from the DR! However, the concepts we’re going to explore apply to 6.x and Expanse as well as any other system where you need to group sets of values and then select one group.
This tip is a shout-out to all the reporting folks still working with MEDITECH C/S or Magic from the DR! However, the concepts we’re going to explore apply to 6.x and Expanse as well as any other system where you need to group sets of values and then select one group.
I’m going to break down some code getting data out of NUR section by section, but the entire script can be found [ here ].
Our goal is to get, with good performance, the last documented response to one or more queries sitting under a NUR intervention (base ID). We don’t want to use a sub-query, as that will kill our performance on large data volumes.
One way to get the last documented set of queries is to establish a LineUp / LineDn structure where we number each documented set, both ascending and descending, then use whichever we want. In our example, we want the last-documented, so that would be LineDn = 1
 To sidebar a bit, there might be a table of codes (CPT, Diagnosis, Procedure) where there is a SortOrder / urn / sequence field (which generally implies an ascending set) but there are duplicates in the field (two 2’s for example), or there might be gaps in the sequencing, and that then throws something off.
To sidebar a bit, there might be a table of codes (CPT, Diagnosis, Procedure) where there is a SortOrder / urn / sequence field (which generally implies an ascending set) but there are duplicates in the field (two 2’s for example), or there might be gaps in the sequencing, and that then throws something off.
But, we can assign the numbering ourselves and adjust to the poor quality data.
We define our own sequencing by making a new, calculated field in the result set – and then use either ROW_NUMBER with OVER and PARTITION; or we use DENSE_RANK with OVER and PARTITION.
Script Section by Section
The attached script has a number of useful things going on it, so let’s work through them one by one:
First, you’re going to want to identify a NUR base ID and a couple of queries that are documented together. In our example, we’re going to use a pre-operative phone call type (query1) and the time spent on the call (query2). If you have an equivalent workflow at your facility, it’s a good example to dig out.
This might look like:

Second, we set up a date range to look at:

Note that all of the changeable parts of the query are set up in advance, at the top of the script, before we do any SELECT-ing. This lets us control them from a single place for our testing, and later if we make this a report, we could make them parameters instead.
 The same goes for @dThruDate – we make sure the ending time is 23:59:59.
The same goes for @dThruDate – we make sure the ending time is 23:59:59.
If we were passing parameters, we would need to treat @dThruDate a bit differently. In this example it backs up a day… when the user is picking a date and passing it in, we want to make sure we advance a day first, then back up onto the end of the selected day.
That 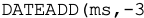 … action there? In a plain SQL DATETIME, the smallest increment of time is 3 milliseconds. So backing up from 00:00:00 of a day by 3 ms, gets you the very last possible point of recorded time in the previous day.
… action there? In a plain SQL DATETIME, the smallest increment of time is 3 milliseconds. So backing up from 00:00:00 of a day by 3 ms, gets you the very last possible point of recorded time in the previous day.
Now we get into the main logic, which set up a SELECT against a SELECT. This demonstrates two things:
One, if you didn’t already know that you can SELECT from another SELECT, you can! You just enclose the inner SELECT in (). This setup lets us build a result-set, including our calculated LineUp and LineDn fields, and then select based on that calculation.
As the example stands to start, we’re not using the WHERE at the bottom, which is associated with the outermost SELECT. We’ll use it later.
Inside the inner select, we define two versions of our LineUp/LineDn calculated fields:
 That seems like quite a bit of code, but it’s really just four variations of the same basic structure:
That seems like quite a bit of code, but it’s really just four variations of the same basic structure:
ROW_NUMBER or DENSE_RANK determine how our sequencing number is calculated. ROW_NUMBER will get you a unique number per row of data in the set. DENSE_RANK will group the rows by the ORDER BY clause and produce one sequence number for each set of grouped rows.
PARTITION then becomes important, because this clause determines when the sequence number resets. In the examples above, each time SourceID + VisitID + BaseID changes, then the numbering restarts.
ORDER BY is also critical, because it determines the order of the sequence numbers. Note that each ORDER BY has a DESC(ending) or ASC(ending) keyword at the end. These are also required, so that SQL knows which way to run the sequence.
In this example we’ve also constructed a sort of our own, by building a three-part key (date – occurrence – activity) so that the sorting works properly. Again, this is something we can do by building our own sequence numbers, something that is not present in the MEDITECH DR data by itself… we are really creating new data out of what exists.
Once the query is configured at your site and you can run it, examine the results. You’ll see how the sorting works in DENSE_RANK vs. ROW_NUMBER, and you can apply that to your own code as needed.
After reviewing the results, uncomment each of the WHERE clauses for the outer SELECT in turn, and see how the data-set changes.

The Use Case
In our example, we’re looking for a set of queries documented at the same time. And then pulling them out as a group (by using DenseRankDn = 1). This lets us treat them as a set, rather than having to noodle around trying to get each one individually.
Using ROW_NUMBER won’t get us that grouped set, but if we only wanted one query response, then we would use it.
A Final Note: The eagle-eyed may have noticed that I aliased/named my calculated fields with this format:
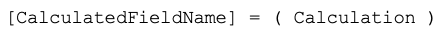
This is a new, standardized format I’ve started using in all of my SQL code. Any data element with an aliased name gets that set on the left side of the line, followed by = and then by the calculation. It takes a bit to get used to it, but it’s more readable and easier to maintain than the way I used to do it:
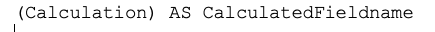
Extra Credit
Take a look at the data again, and you’ll see that grouped queries do share SourceID, VisitID, BaseID, OccurenceSeqID and ActivitySeqID. This means that we could get one query in the main FROM, and then do a LEFT JOIN to get the results of specific other queries in the set.
Try that out! Make the response for the second query appear as its own column.
And…
As ever, if you need help with MEDITECH DR optimization, reporting, extract, index creation or analysis please feel free to give your iatricSystems Account Executive a call!
