Written by Thomas Harlan, Reporting Services Team - iatricSystems

As we go through our daily lives of reporting and analyzing data, we use SELECT constantly. It’s like breathing after a while… and while we might be keeping an eye on the performance of our queries, so that we don’t use unnecessary system resources, they generally don’t crash out on a resource constraint issue and interrupt other processes. SQL Server is good at managing them.
If we use an INSERT command to load data into a new (or existing) table, we might be thinking about disk space usage. We wouldn’t want to duplicate some giant table in its entirety – first why would we duplicate it when we already have a perfectly good copy? And second, you don’t want to do SELECT * INTO SomeNewTable FROM BiggestTableYouHave anyway, because that’s what a JOIN is for.
We use INSERT to load small temp tables, primarily when we want to create an index on those tables which does not already exist on the source table, or if we are driving a multi-step query with a selector table.
Less often, we use DELETE.
We get into using DELETE – NOT for LIVE data in the MT-released tables! – when we’re working with a custom data structure (either a physical table we’ve created, or a temp table) in three main ways:
For scenario #3, we really want access to TRUNCATE TABLE because it’s very fast, but we can’t always get it.
For the other two use cases, we are not looking to kill all the rows in the table, only some, and TRUNCATE TABLE is right off the… ah, table, at that point.
DELETE poses a problem, however. Unlike a SELECT, it is a logged operation. By that we mean that if something happens in the middle of the DELETE to interrupt the process, SQL Server is looking to unwind the DELETE, and put everything in the database back where it was at the beginning.
Which means your DELETE command is chewing up log space when it runs.
Now your log clears out on a regular basis, because you’ve got a database backup running (you do, right? Right!?) and the backup job issues a CHECKPOINT command which clears and resets the logging system.
But that CHECKPOINT might not be happening every day (should it? Yes, it should, because you should be taking an incremental backup of the DR each day) which means that by the end of the week, there might be a heavy hit on your logging space. (Will there always be? No, every transaction might have successfully cleared out during the week, releasing the space in the log.)
If you then jump into a DELETE operation involving hundreds of thousands or millions of rows, then you might fill up the log, the DELETE will die, and other running processes could be adversely affected, including the DR xfer process that is constantly punching new data into your DR.
This means that unless you are very certain that the DELETE is affecting only a small number of rows, you need to handle it differently. You want, in fact, to break up the DELETE into smaller chunks that will finish faster, use less log space, and then release it quicker when they are done.
We do this with a looped DELETE, which kills 10,000 rows per pass. In the following example, we’re using a staging table which is filled each day with all of the PCS assessment + query + response rows updated in the previous day, and we’re comparing it to a reporting table which contains a row per query + response for ad-hoc querying by the site:
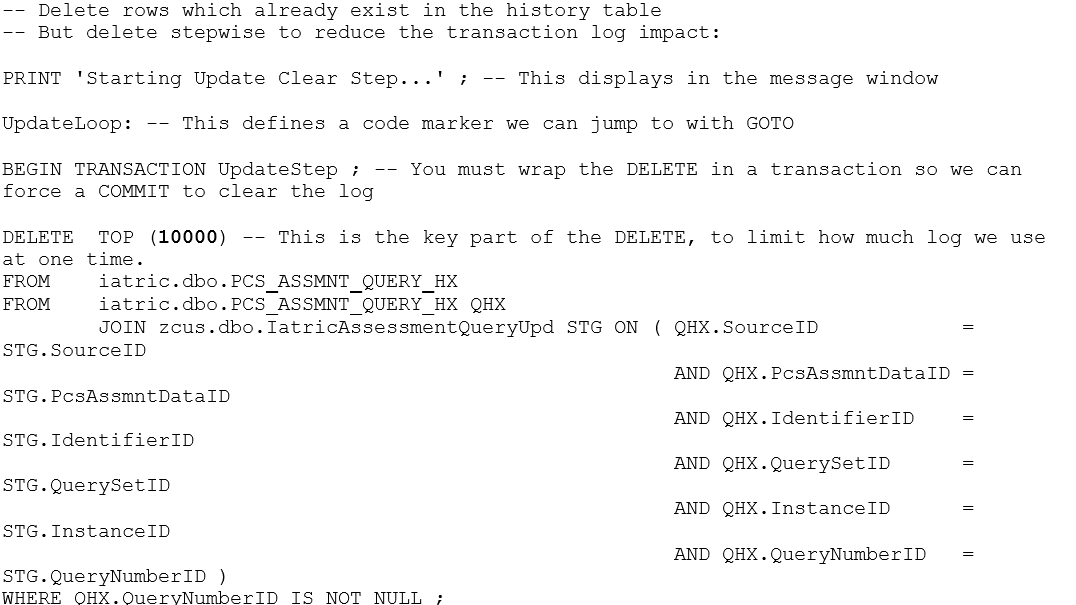

This general pattern can be used repeatedly. In this bigger process we also use a looped DELETE to clear out assessment records that are more than four years old, to keep the assessment table from growing out of control.
Extra Credit
All of this reminds me we need a tip covering the differences and advantages / disadvantages of an UPSERT vs. MERGE vs. DELSERT for loading data into a table over time. Look for that soon!
And…
As ever, if you need help with MEDITECH DR optimization, reporting, extracting, index creation or analysis please feel free to give your iatricSystems Account Executive a call or email info@iatric.com to discuss how we can help support your team!

