Written by Thomas Harlan, Reporting Services Team - iatricSystems

Essentially every table that you access in the Meditech DR has a SourceID field embedded as part of the primary key. If you are a single facility system, you generally wind up having only a single value for your SourceID across all tables and modules.
Let us say that is the value: IAT
However, if you have multiple facilities in your MT setup, then it is quite likely that each NPR module will have a facility-specific SourceID to identify the data, in each DR table, from each facility. If our theoretical system of hospitals has three facilities, we might have:
IA1
IA2
IA3
…as the NPR-generated SourceID(s) in tables populated with data from NPR modules.
In M/AT modules, in comparison, you will only see one facility ID. IAT, in this example.
One of the quickest ways to drag down the speed of your queries is to NOT include as many of the components of a primary key in a JOIN statement as possible, so if you happen to be leaving out SourceID in every single JOIN you write, then you are leaving speed on the table.
Which makes things interesting when you have multiple facility-specific SourceID values.
Now if you are going from the visit table to other visit-keyed tables, you can just use the SourceID from the base table in all your JOIN(s) and you are done.
But often we have to bridge across modules, and then the specter is raised that the DR table from the other module has a different SourceID than the table we are JOIN-ing from, and that means we’re not going to get a match.
(Usually this occurs when we are going from a data table, with a facility-specific SourceID, to a global dictionary table, where there might be a separate MIS-specific SourceID)
We need a way to identify all the Source ID’s, per facility, per module.
Luckily, Meditech provides reference tables of each module, per facility, and the SourceID’s they use. We just need to reconstruct that table into a form that is easy for us to use in our code:
First, you want to make sure that these tables are populated in your DR:
| NPR | |
| DMisFacilities DMisFacilityDatabase |
|
| M/AT | |
| MisFac_Main MisFac_Databases MisHimDept_Main |
Those tables represent our data in one row per facility per module database. We do not want it to look exactly like that, so we PIVOT the data into a one-row-per-facility format:
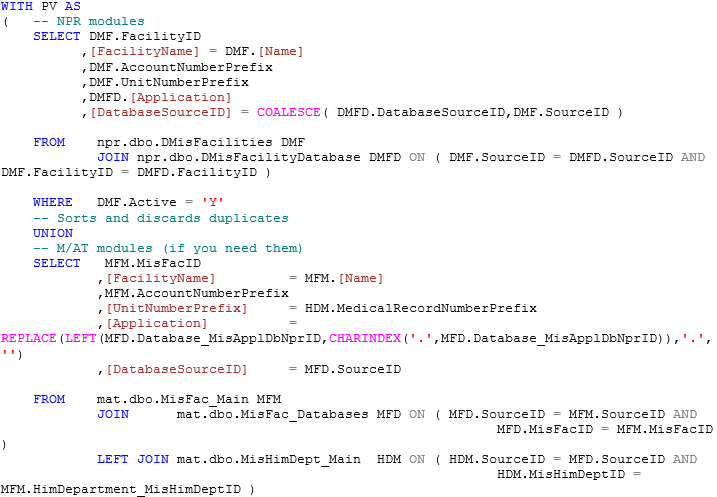

That produces output like this (columns on the right-hand side have been removed to make this fit, by the way.)

You could use this structure in your code by: creating a VIEW to contain it globally, or a Common Table Expression per query, or by populating a Temp Table in each stored procedure that needs it.
Creating a temp table, with an appropriate primary key, gives you the fastest performance of this structure in your code. [ Source Code Attached! ]
Extra Credit
Write some dynamically constructed SQL to build that list of Application Database ID’s for the PIVOT from the available data itself, rather than hard-coding them.
And…
As ever, if you need help with MEDITECH DR optimization, reporting, extracting, index creation or analysis please feel free to give your iatricSystems Account Executive a call or email info@iatric.com to discuss how we can help support your team!

