Written by Thomas Harlan, Jim McGrath; Reporting Services Team - iatricSystems
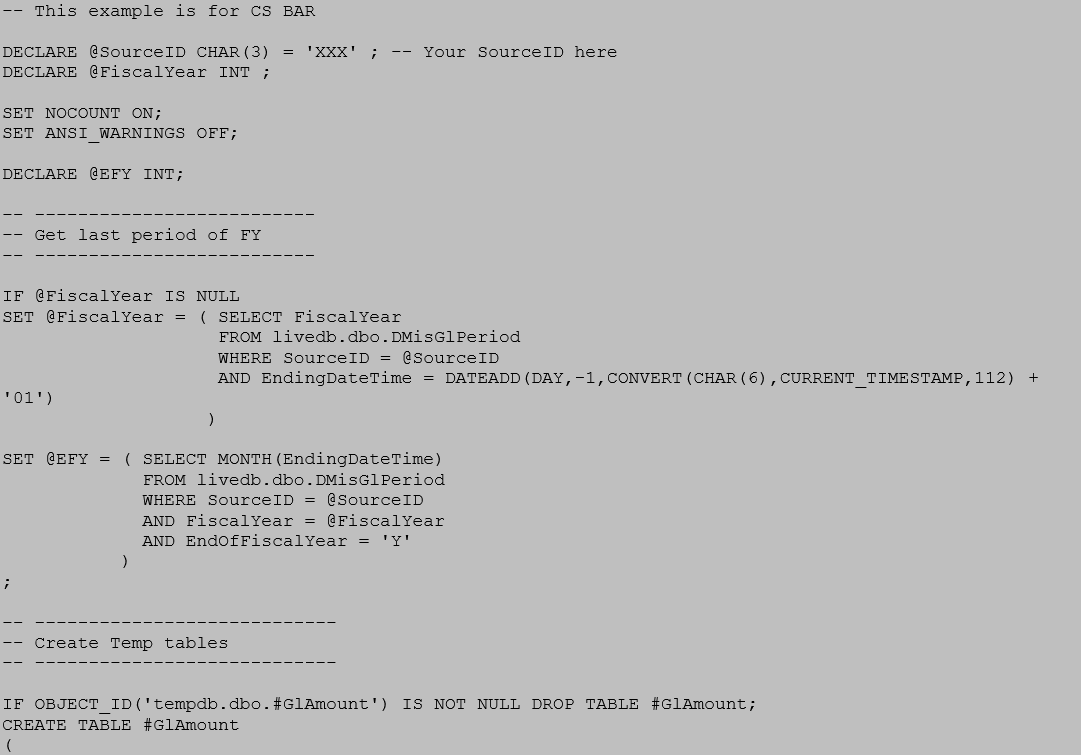
 Because SourceID is part of the primary key in virtually all MEDITECH Data Repository tables, it is good practice to include SourceID as the first column all indexes, include it in all joins and to identify SourceID in the WHERE clause of the query. In most cases this will cause SQL Server to use an index seek instead of an index scan and greatly improve performance.
Because SourceID is part of the primary key in virtually all MEDITECH Data Repository tables, it is good practice to include SourceID as the first column all indexes, include it in all joins and to identify SourceID in the WHERE clause of the query. In most cases this will cause SQL Server to use an index seek instead of an index scan and greatly improve performance.
In simple terms an index seek will rapidly find the requested set of rows by using an index and then stop; where an index scan (or table scan) will examine every row to determine if it meets the criterion.
The performance impact can readily be imagined in a table with 10 million rows of which only 100,000 have SourceID = <xxx>. The index seek examines only 1% of the rows that a scan must check to return the same result set.
In the query below, a pivot is used to capture a year’s monthly GL amounts in a single row and store them in a temp table ( #GlAmount ). In this case #GlAmount is a heap so any query plan will use a table scan on #GlAmount. We expect this to be acceptable because every row in #GlAmount will be used in the subsequent query.
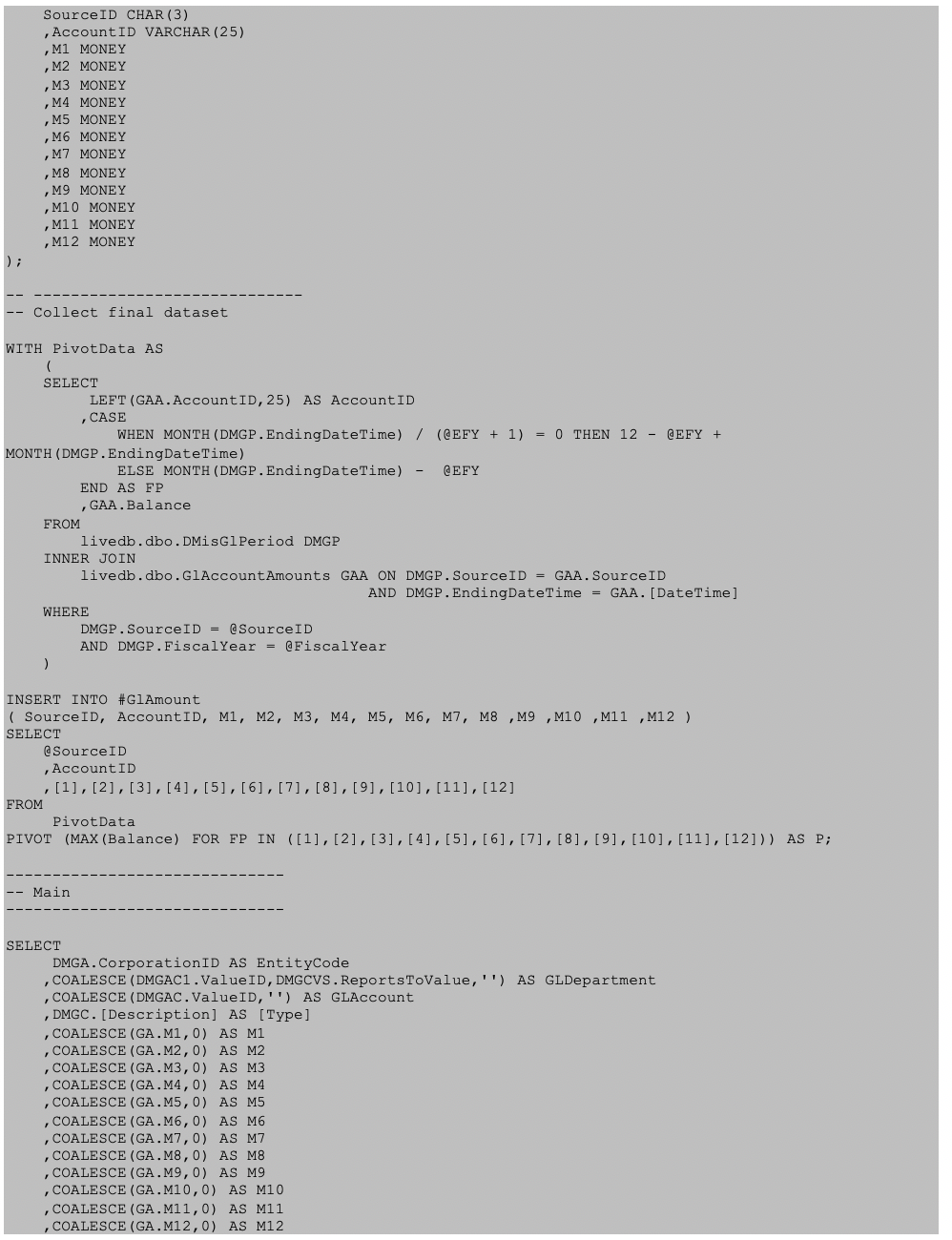
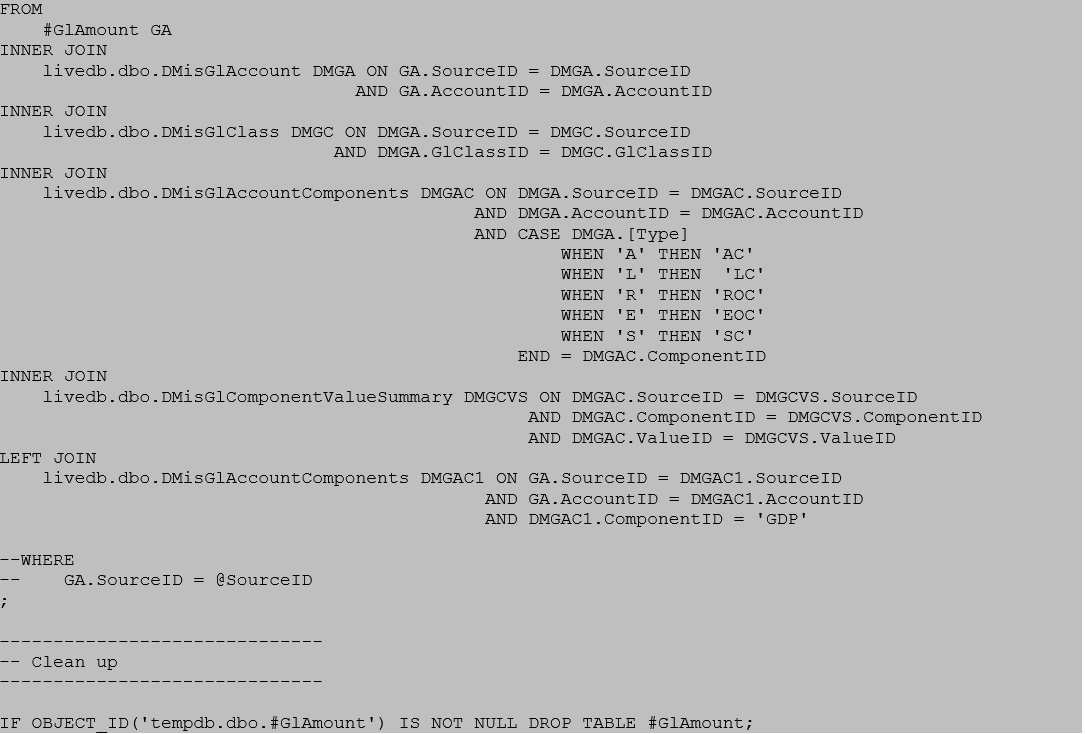
The T-SQL query optimizer will create several plans to accomplish its task. In this case we are only interested in the last plan in the batch.
Following good practice, we include SourceID in all joins (but not in a WHERE clause because we are using every row in #GlAmount) and we expect to see clustered index seek(s) throughout the execution plan.
Examining the resulting plan, however, we find that all tables are using clustered index scans instead:
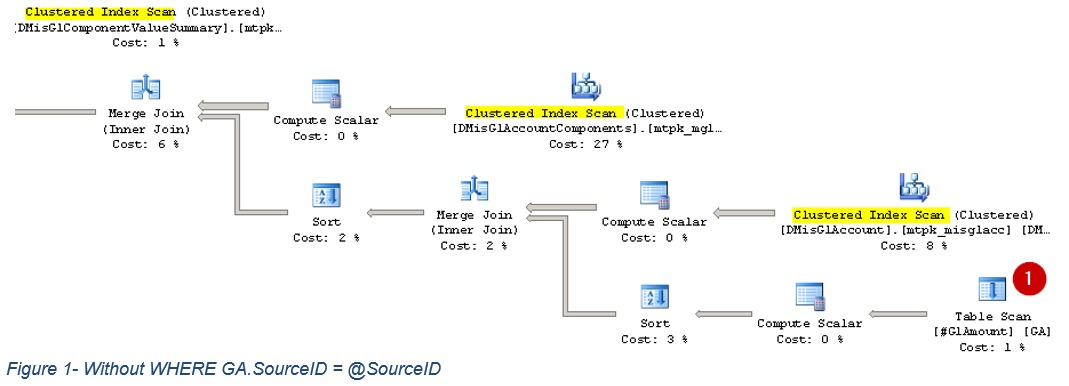
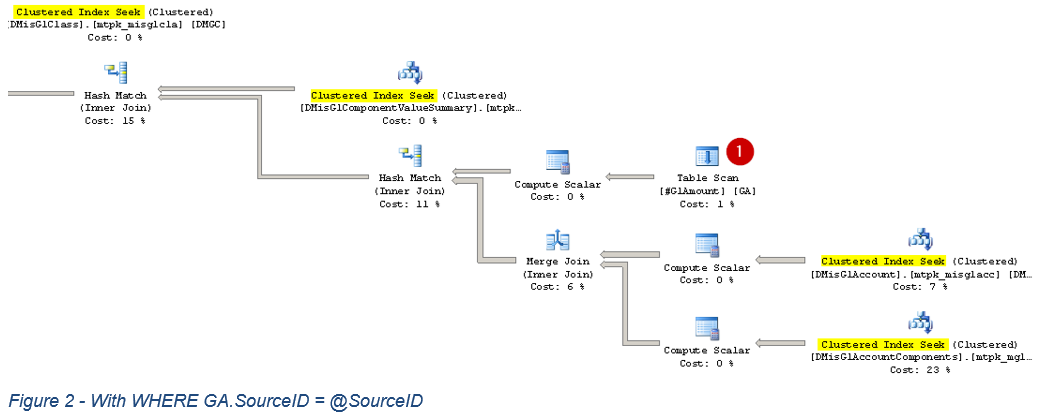
Now add WHERE GA.SourceID = @SourceID (uncomment the last two lines of the main query) and rerun the query.
Examining the execution plan, we are still using a table scan on #GlAmount, but all other tables are now using a clustered index seek.
Additional Notes
There is a point where using a clustered index as a temp table costs more than it will save in performance, as the table must be created, the primary key set, and then data loaded and sorted into primary key order. Unless the temp table is very large, defining it as a heap may result in better performance.
Unless a temp table is very small, it is usually better to use a temp table rather than a table variable. Temp tables are included in statistics where table variables are not. Having table variables in the mix often results in very poor performance. Because of this we avoid them as a rule, unless we need to use them as a result set collector for a table-valued function, or possibly to pass as a parameter. Even in those cases, sometimes it is more performant to copy the contents of the table variable into an indexed temp table before JOIN-ing to anything.
Defining a temp table using CREATE TABLE is preferable to SELECT INTO #table. Explicitly defining the temp table makes the code more readable (Think of the 1,000 line stored procedure you wrote three years ago that you need to go back to modify. Even worse the code someone else wrote) and allows you to define a PRIMARY KEY CLUSTERED during the create step.
The summary takeaway here is: always use SourceID in any JOIN or WHERE, even in temporary tables.
And…
As ever, if you need help with Meditech DR index creation, reporting, extract or analysis please feel free to give your Iatric Systems Sales Representative a call!
Our Report Writing team can help with Data Repository reporting, NPR report writing, data extract or analysis, and much more. Simply reach out to your iatricSystems Account Executive or email info@iatric.com to discuss how we can help support your team!

