Written by Thomas Harlan, Jim McGrath; Reporting Services Team - iatricSystems

It's common in MEDITECH’s 6.x Data Repository (DR) to encounter fields in PCM or EMR where a single long text field contains a packed data structure. For example, when a multi-select item has been stored with a variety of delimiters and special formatting. If you haven’t run across these fields before, here’s an example from EMR where we’re looking at the Discharge Problem field, which is a standard field attached to a documentation section for Clinical Impression:

As you can see, we get a variety of data items:
We could just display the entire field – strange formatting and all – but that won't help our end-user, who just wants to see a readable problem list on the report. Something like:
![]() What we must do, then, is split each field into a table-structure where there is one row per problem. We can see from the data that a “}|{“ delimits each problem entry. Inside each entry, we want to check for the sixth item (delimited by |) for a description (rows 1 and 3), and if there’s nothing there, then we use the first item (which in this data is a free-text string beginning with a period), instead.
What we must do, then, is split each field into a table-structure where there is one row per problem. We can see from the data that a “}|{“ delimits each problem entry. Inside each entry, we want to check for the sixth item (delimited by |) for a description (rows 1 and 3), and if there’s nothing there, then we use the first item (which in this data is a free-text string beginning with a period), instead.
Using record three as an example, we’ll go from one row delimited by }|{ into two sections:
![]() To two rows…
To two rows…
![]() And then break out the sixth element of each row:
And then break out the sixth element of each row:
 But… when we get at the data like this, we will often get this error:
But… when we get at the data like this, we will often get this error:
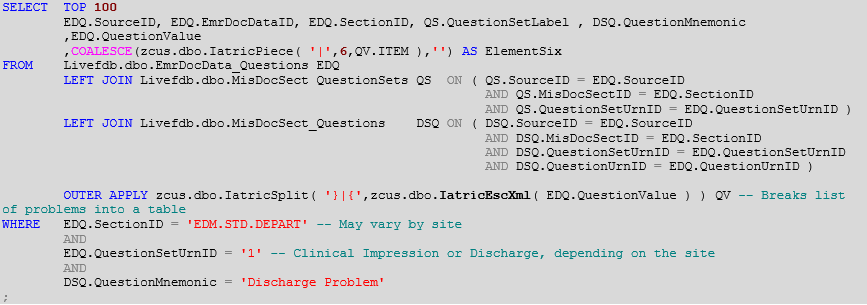
In our DR Resource Center, we use a CTE/tally-table approach to avoid using XML XPATH to do the split. But we can also “escape” the reserved characters into their XML equivalents (also called an entity reference):
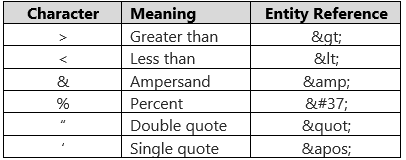
That % one is a Microsoft-specific extension, and not part of the XML standard. However, since you’re using SQL Server to do this processing, you must account for it. To make this easier, we created a little IatricEscXML() function to do the swapping out… [code!]
Then we can mix that in and get…
 If you’ve been up on MEDITECH 6.x for some time, when you run this code against your real data, you will likely see that the older data doesn’t follow the structure for this field we’ve shown above (with six elements in each problem string), but the more recent data does:
If you’ve been up on MEDITECH 6.x for some time, when you run this code against your real data, you will likely see that the older data doesn’t follow the structure for this field we’ve shown above (with six elements in each problem string), but the more recent data does:
We just need a little cleanup to remove the leading and trailing {{}} characters, so we add a pair of REPLACE(s) to get rid of that.
Maybe you notice that in addition to picking an IMO Problem from a list, the person doing the discharge documentation can also enter complete free-text, which is prefixed with a period:
To address that, we add a CASE statement as well, to see if element six is empty, and if it is, then get element one instead. And finally, we use XML PATH(‘’) to create a list of problems (if there are more than one), separated by ; characters for displaying on a report.

Now we have something we can reasonably display to the end user.
Extra Credit!
Create a table-valued function based on this example, allowing you to JOIN to this data structure without the performance impact of making it a VIEW.
If you need more help…
Our Report Writing team can help you fix reports, create new ones, make old ones faster, and much more. Simply reach out to your Iatric Systems Account Executive or our NPR report writing team at reportwriting@iatric.com to discuss how we can help support your team!

