Written by Thomas Harlan, Jim McGrath; Reporting Services Team - iatricSystems
 Ignore SourceID at your peril!
Ignore SourceID at your peril!
When creating joins in a SQL query, best performance is often attained by including as many primary key columns in the JOIN predicates as possible. In Meditech’s Data Repository, the SourceID column is often overlooked, especially by SQL newbies. SourceID is the first primary key column in virtually every table in Data Repository databases and simply adding this column to your joins can improve performance dramatically.
An additional important factor is to explicitly identify the value of SourceID for the main (FROM) table in the WHERE clause. Here we discuss this one factor in query performance:
Our query (Note we are only capturing the first 100 rows):
SELECT
TOP (100)
COALESCE(MP1.[Name],MP.[Name]) AS PatientName
,MPUN.UnitNumber
,COALESCE(MPVE.VisitAccountNumber,MPVE.VisitAccountNumber) AS AccountNumber
,COALESCE(MP1.Confidential,MP.Confidential,MPVE.Confidential) AS Confidential
,COALESCE(MP1.EmrRecordSealed,MP.EmrRecordSealed,MPVE.SealedEmr) AS RecordSealed
,DMF.FacilityID
,DMF.[Name] AS FacilityName
,MPVE.VisitDateTime
,MPVE.DischargeDateTime
,MPVE.[Status]
,MPVE.VisitType
,MPVE.LocationID
,MPVE.ProviderName
FROM
MriPatients MP
LEFT JOIN
MriPatients MP1 ON MP.SourceID = MP1.SourceID
AND MP.MergedToPatientID = MP1.PatientID
INNER JOIN
MriPatientVisitEvents MPVE ON MP.SourceID = MPVE.SourceID
AND COALESCE(MP1.PatientID,MP.PatientID) = MPVE.PatientID
INNER JOIN
DMisFacilities DMF ON 'XXX' = DMF.SourceID
AND MPVE.VisitAccountNumber LIKE DMF.AccountNumberPrefix + '[0-9]%'
INNER JOIN
MriPatientUnitNumbers MPUN ON MPVE.SourceID = MPUN.SourceID
AND MPVE.PatientID = MPUN.PatientID
AND DMF.UnitNumberPrefix = MPUN.PrefixID
WHERE
'XXX' = MP.SourceID
;
By using TOP(100) we expect SQL to capture 100 rows and stop, returning a result set very quickly. We execute this query twice, first without the WHERE clause then with the WHERE clause. Run 1 completed in 44 seconds, run 2 completed in zero seconds. The partial execution plans (following…) show the different ways the SQL optimizer generated the plans.
Note that all MRI tables are children of MriPatients and the DMisFacilities join is determined from a column in the third (MriPatientVisits) table. We can expect the execution plant to begin with MriPatients as all other tables are dependent on this table. However this is not the case due to one factor:
Identifying SourceID for the first instance of MriPatients:
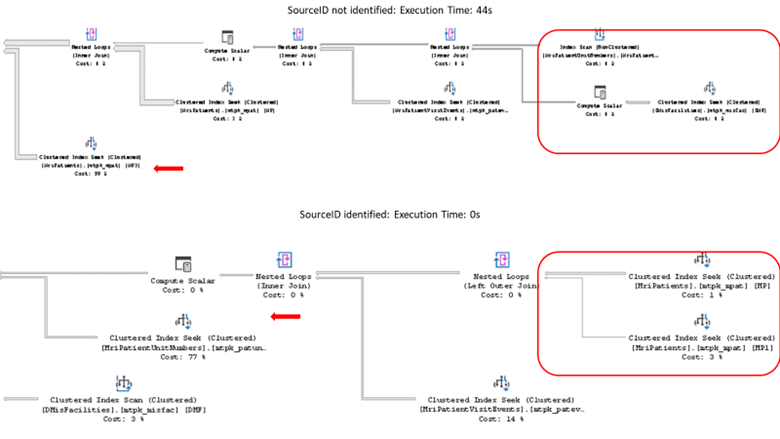
Figure 1: Beginning of execution plans
There are two major points where the execution plans differ: how the queries begin and the performance of the operation with the largest impact.
Run 1, without the WHERE clause, starts with the DMisFacilities table and joins with the MriPatientUnitNumbers table. The clustered index seek on DMisFacilities is executed 57 times, not a significant impact because DMisFacilities contains only a few rows. Imagine the impact if DMisFacilities contained even 10,000 rows. The MriPatients is not included until the fourth and fifth tables joined.
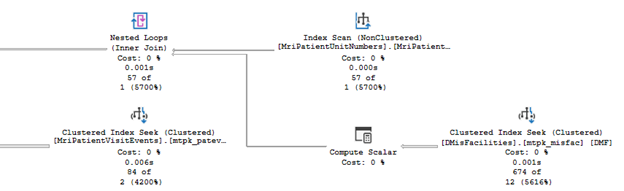
Figure 2: Run 1 execution plan beginning
Run 2 tells a different story:
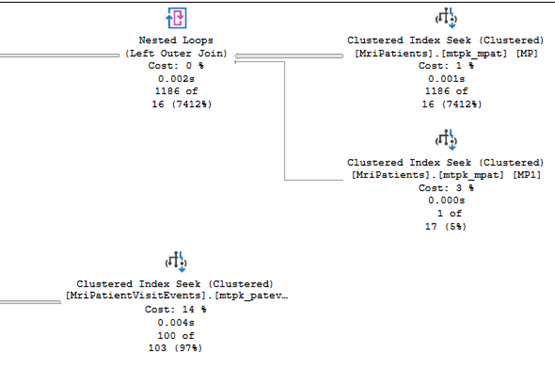
Figure 3: Run 2 execution plan beginning
Run 2 begins with the shortest search, MriPatients and the join with itself (captures merged patients). The cluster index seek is executed one (1) time.
How about the heavy hitters? Once again, we see large differences:
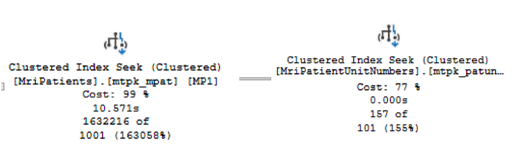
Figure 4: Run1 vs Run2 major impact
Run1 conducts a whopping 34,560,401 clustered index seeks on MriPatients and returns 1,632,216 rows to be filtered further along in the plan.
Run2 conducts 157 clustered index seeks and returns 157 rows.
Your DR, your users and all of us here at Iatric beg you! Don’t forget SourceID!
Extra Credit
Do you have custom VIEW(s) set up in your DR? Review each one, making sure each JOIN includes SourceID, and then set – where you can – the SourceID for the main FROM table in each VIEW. This gets you the most coverage, for this optimization, with the least work. Then whenever you create / modify any of your DR-based SQL … make sure to check your SourceID usage and update wherever possible!
And if you need help with MEDITECH DR optimization, reporting, extracting, index creation or analysis please feel free to give your iatricSystems Account Executive a call or email or our NPR report writing team at reportwriting@iatric.com, to discuss how we can help support your team!

