Written by Thomas Harlan, Jim McGrath; Reporting Services Team - iatricSystems

It may not be obvious when working in SQL Server Data Tools or Business Intelligence Development Studio, but when you add datasets to a SQL Server Reporting Services (SSRS) Report, they get an implied order of execution. Say you have a MEDITECH EDM dashboard, and it has some datasets that control parameter lists, and then two datasets that call stored procedures to get patient data and calculate median timings:
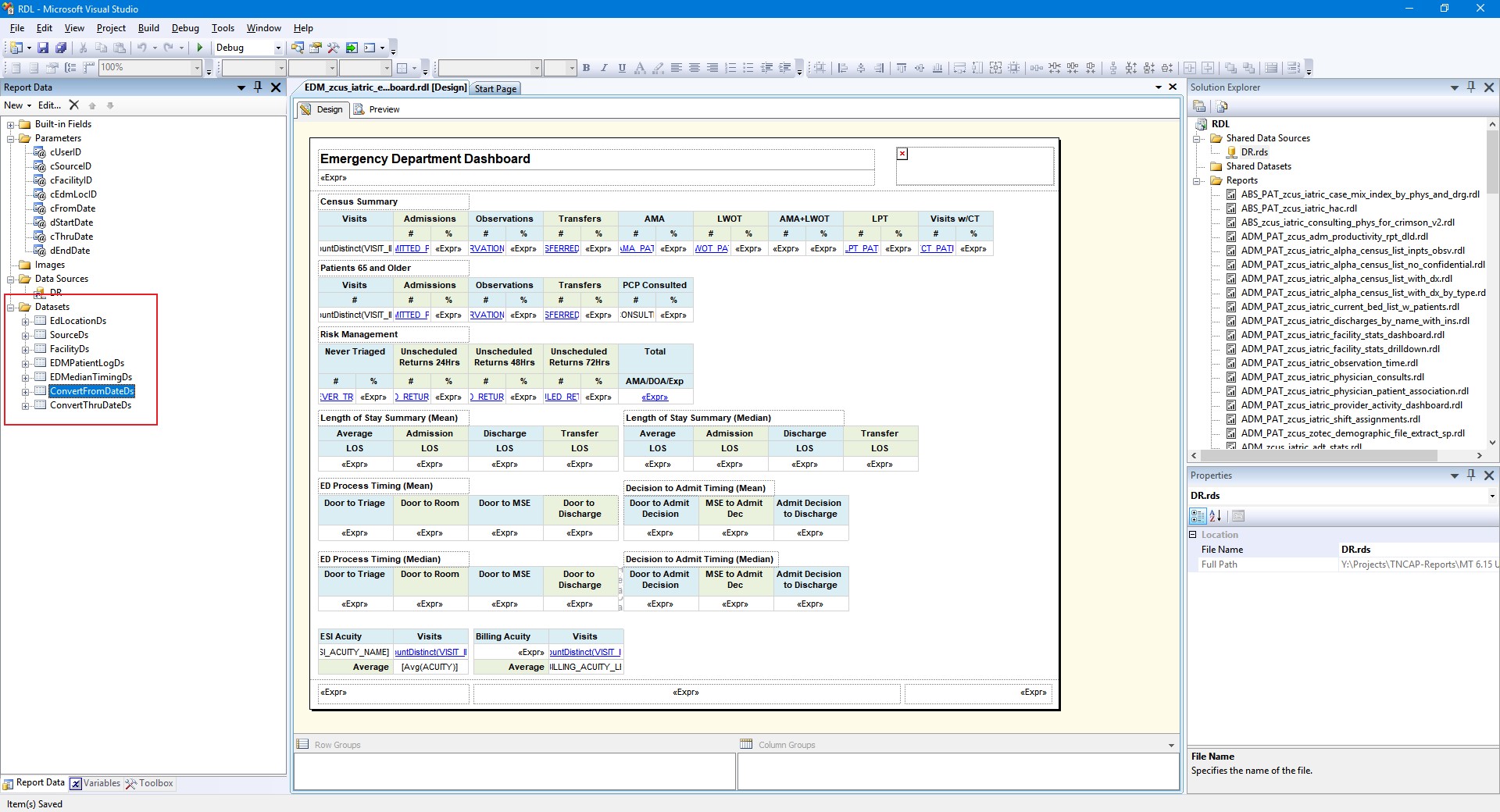
As the report sets itself up and displays the parameter pane to you, any datasets driving parameters are executed if they don’t have cross-dependencies. In this example, the datasets for SourceDs, FacilityDs, EdLocationDs, ConvertFromDateDs, and ConvertThruDateDs are all needed by the parameter pane, so they will execute as needed while the user is entering / picking parameters.
By default, whenever possible, the SSRS Report Manager (or the DataTools developer) will parallelize the queries to speed up the whole report.
EDMPatientLogDs and EDMedianTimingDs are a different matter. These two datasets call stored procedures to get and process data for the report, and they don’t fire off until the user views the report. As it happens, EDMedianTimingDs needs data from EDMPatientLogDs, so we can’t have them run in parallel. The PatientLog needs to fetch everyone first, and then MedianTiming will figure out the median (not mean) averages of timing points for those visits.Note! SSRS 2008-2017 does not have a built-in Median() function as part of its set of aggregate calculations, so we had to build a separate process for this calculation. You can do this entirely in SSRS, or in SQL. We went the SQL route so the calculation could be re-used in multiple reports and the code maintained in one place.
An additional concern with this parallelization is that both datasets hit the same tables… That means we could cause inadvertent blocking by having two queries running that look at the same EDM visit set, and thus the same data pages, at exactly the same time.
We can get around these issues by forcing the datasets for the report proper to serialize, or run one after the other. Then they don’t block, and PatientLog can run and complete before MedianTiming runs.
In SSRS, this is controlled by a setting on the report Data Source. In our example, you get to the setting by right-clicking on Data Sources > DR and choosing Data Source Properties. Then you checkmark “Use single transaction when processing the queries.”
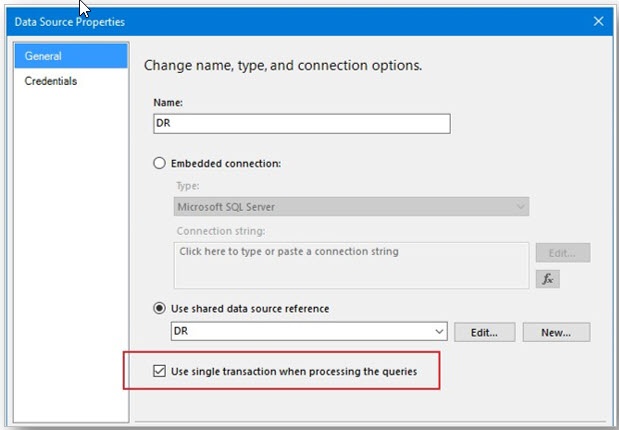
Once you do this, the processing of the datasets changes. They now run in the order they are listed in the Report Data explorer, under the Datasets node, unless they are used by the Parameter pane.
So, in our example, since EdmPatientLogDs is listed first, it will execute before EDMedianTimingDs. This avoids potential blocking and ensures they execute in the order we expect.
Note! This setting exists only at the Report level. You cannot set it in the shared Data Source for the entire project, which is as intended (and a good idea).
As a side effect, both stored procedure calls are now automatically executed as a transaction, so either both succeed, or the entire process errors out.
Note! There is no way to re-order the Datasets once they are added to the report without hacking the RDL itself. So, either you set them up in the desired execution order from the get-go, or you delete and re-add them, or you edit the XML.
Extra Credit
You do know that you can have multiple datasets on a report and have each dataset drive a separate Tablix on the same report, right? And you know they can all share the same set of parameters, right? This is very handy for dashboards!
If you need more help…
Our Report Writing team can help you fix reports, create new ones, make old ones run faster, and much more. Simply reach out to your Iatric Systems Account Executive, or our NPR report writing team at reportwriting@iatric.com, or click the button below to contact us and learn how we can help support your team!

