Written by Thomas Harlan, Jim McGrath; Reporting Services Team - iatricSystems

One of the few custom objects you want to add to your MEDITECH LIVE or TEST Data Repository (DR) databases are indexes. An index can speed up reporting by fetching records based on specific fields, like Service Date. MEDITECH themselves release only a few indexes, mostly focused on Meaningful Use reporting.
You can add your own indexes as you need them. And if you have inherited a DR database, others may have gone before you and done just that. So, when you want to add an index, check to see what indexes are in place on the table first. You don’t want to duplicate something that already exists!
![]() But sometimes that happens anyway. Multiple people may have access to create indexes, and may not have been cross-checking or coordinating with one another… This can result in duplicated structures.
But sometimes that happens anyway. Multiple people may have access to create indexes, and may not have been cross-checking or coordinating with one another… This can result in duplicated structures.
The effects of duplicate indexes aren’t fatal, but they don’t help you, either:
How do we find duplicate indexes?
For a given database (and generally we’re only worried about your livedb), we can run a script which creates a list of all custom indexes and what composes them, by querying sys.index_columns and sys.columns.
At this point, the wise among you may point out that there are some truly lovely scripts you can get on-line that will automatically crunch the indexes and warn you of duplicates – like BlitzIndex, for example. And that is entirely true, but you may find (depending on your security access to livedb) that you cannot run those sophisticated scripts because they require access to System Dynamic Management views, particularly if you are in a hosted environment.
But if you have SQL access to livedb to build reports, then you can, very likely, see sys.index_columns and sys.columns, and that means a simpler script that just looks for duplicated key sets might work for you.
In that script, however, we want to exclude some indexes from our search, because we don’t want to kill anything critical. So, we exclude:
Then we want to pull in our list of key columns, any index filtering clause, and any included / covering columns. Once we have that, we rank them by the Table and Column(s) fields, and if we exclude IndexRank = 1, then we have the potential duplicates.
Our query looks like this:

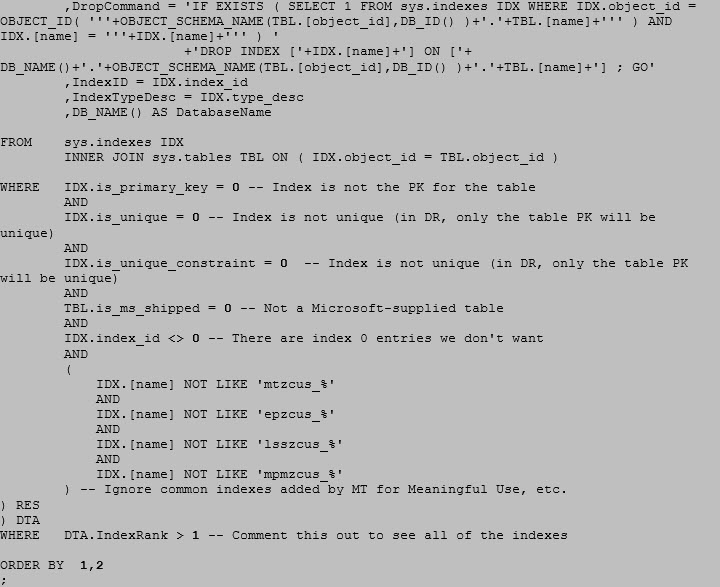
Note we’re using that FOR XML PATH (‘’) technique to create a delimited list of key columns and (potentially) included columns. We also use ROW_NUMBER() to assign a line count to each index on each table, and then when we filter everything that isn’t IndexRank = 1 at the end, we get our potential duplicates.
But Wait!
This query sorts the column list by column name, which means I could have two different indexes with different arrangements of the same columns:
![]()
Does that matter? The answer is yes… Sometimes. 8-)
If a vendor has created duplicates with different column orders, then leave them be.
If you or a co-worker have created them, put your heads together to determine if you can decommission one of them. Generally speaking, you can do so by taking a look at the selectivity of your queries against that table.
In the example above, if you are WHERE-ing/JOIN-ing primarily by VisitID, then you want the first index. But if you’re JOIN-ing or WHERE-ing by SourceID and VisitID and you have more than one SourceID in your environment, then you probably want the second one.
Automating the Cleanup
As a helpful bonus in this query, we also automatically compose the DROP command for each index in the DropCommand column. This lets you select just that column and copy/paste into a new .sql script to get going with your cleanup of those pernicious extra knids, I mean indexes.
Extra Credit
Add a NaturalOrderColumns field which shows each index’s columns in their structure order – that is, not sorted alphabetically.
If you need more help…
Our Report Writing team can help you find duplicate indexes, parse fields, fix reports, create new ones, make old ones faster, and much more. Simply reach out to your Iatric Systems Account Executive, or our NPR report writing team at reportwriting@iatric.com), or click the button below to contact us to discuss how we can help support your team!

